
大数据平台——数据中台建设实战
大数据平台——数据中台建设实战
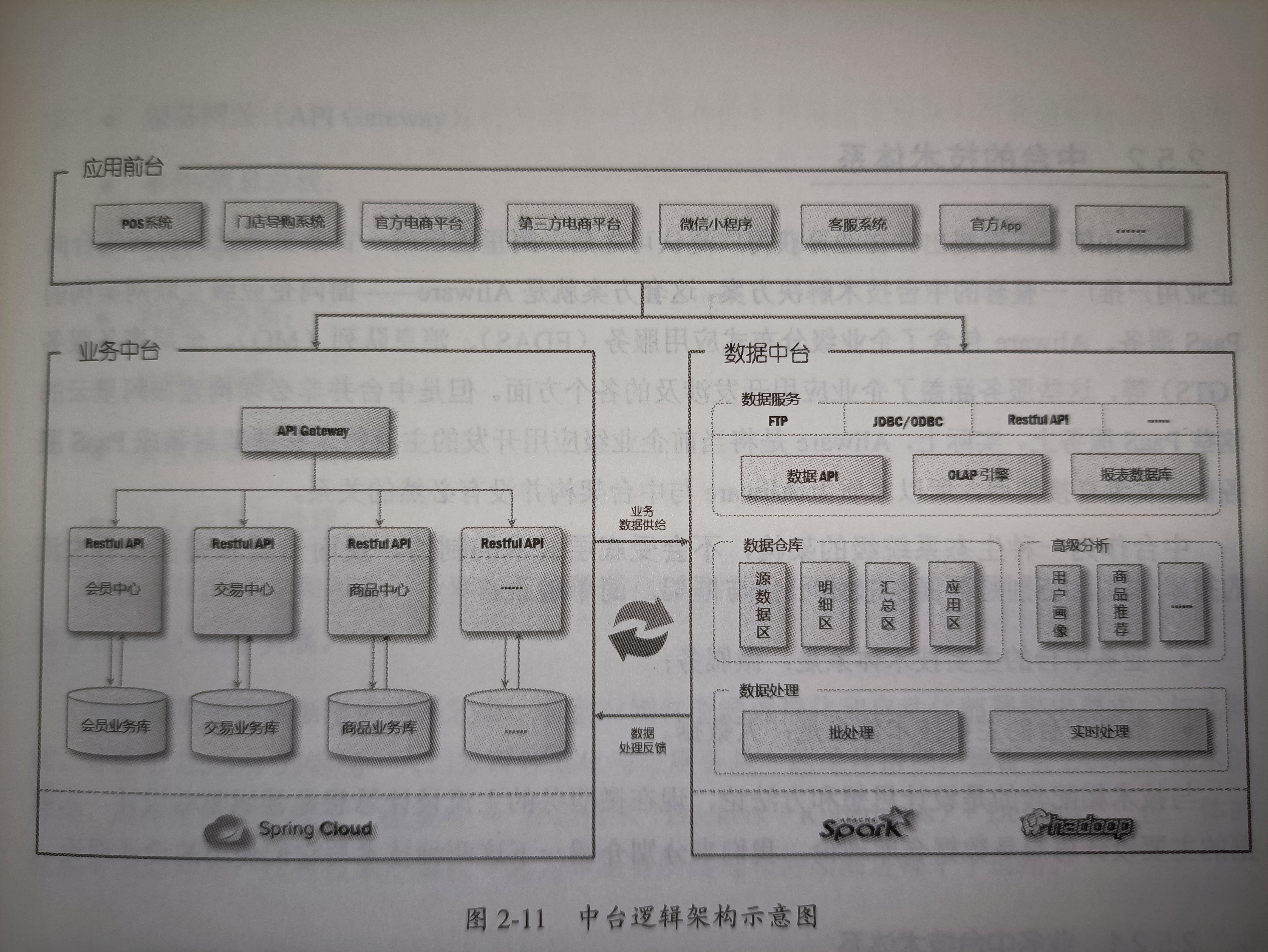
业务中台技术体系
微服务:
服务注册与发现
服务配置管理
服务网关
事件/消息总线
负载均衡
容错与熔断
监控与报警
安全和访问控制
日志收集与处理
数据中台技术体系
Hadoop、Spark:
数据采集
存储
消息队列
批处理
实时处理
作业调度
数据中台具备的能力
1.平滑自如的水平伸缩能力,从容面对海量数据
2.对资源拥有细粒度的控制能力,支持多任务、多用户下的作业处理
3.强大的事实处理能力
4.参与业务请求处理的能力
5.具备人工智能以及机器学习的数据分析能力
6.以数据仓库理论管理和组织各类数据
7.对外提供强大的数据服务,支持多种协议的数据传输与交互
8.拥有完善的数据治理体系,保障数据质量
9.精准的细粒度安全控制
集群安装过程
1.对每个节点做一些必要的前期处理——环境预配置
2.安装MySql集群——安装Galera(MySQL集群),安装Redis
3.安装Cloudera Manager,通过Cloudera Manager安装CDH——搭建本地CDH仓库,配置CDN server,安装CDH
4.对特定核心服务进行高可用配置
架构原型
1.Lambda架构
将批处理作业和实时流处理作业分离,各自独立运行资源相互隔离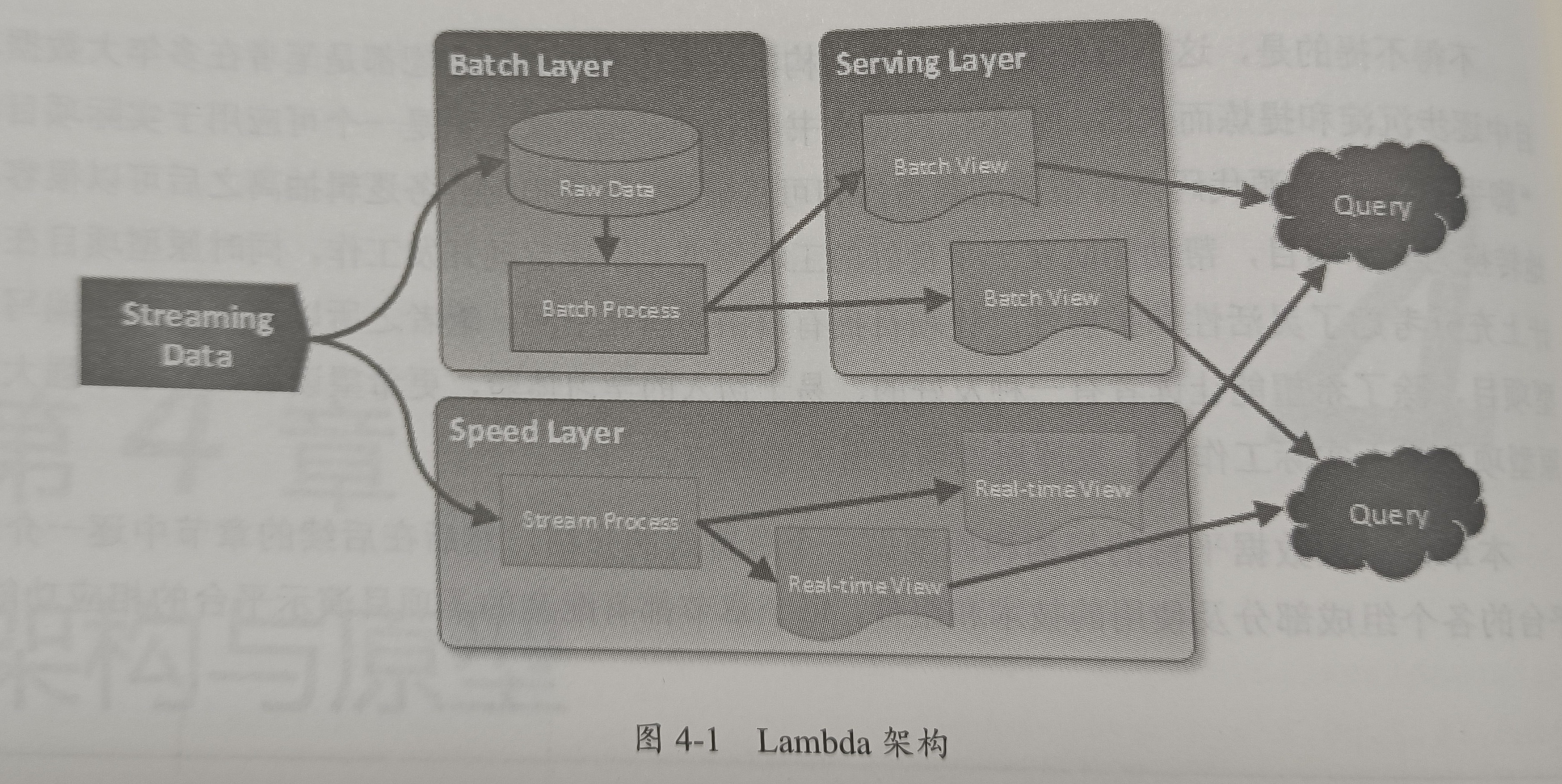
Batch Layer
主要负责所有的批处理操作,支撑技术以Hive、Spark-SQL或Map-Reduce这类批处理技术为主。对数据处理的主依赖进行维护
Serving Layer
以Batch Layer处理的结果数据为基础,对外提供低延时的数据查询和ad-hoc查询服务
Speed Layer
使用流式计算技术实时处理当前数据。只能以实时的方式处理大量数据,只能处理当前新产生的数据,无法对全部历史数据进行操作。常用Storm、Spark Streaming、Flink等大数据流计算框架
Lambda架构使用两条数据管道来分别用对两种场景,因此有数据冗余,健壮但是需要同时维护两套代码,增加了工作量和维护成本
Kappa架构
对Lambda架构的一种简化使用流计算技术统一批处理和实时处理两条数据处理的pipeline
需要的技术组件:前端需要接入一个消息队列(Kafka)
后接流计算框架(Flink、Spark、Streaming、Storm,以流计算框架为主)
SMACK架构
SMACK:Spark\Mesos\Akka\Cassandra\Kafka
利用选型组件的特性,以自然和平滑的方式统一了批处理和实时处理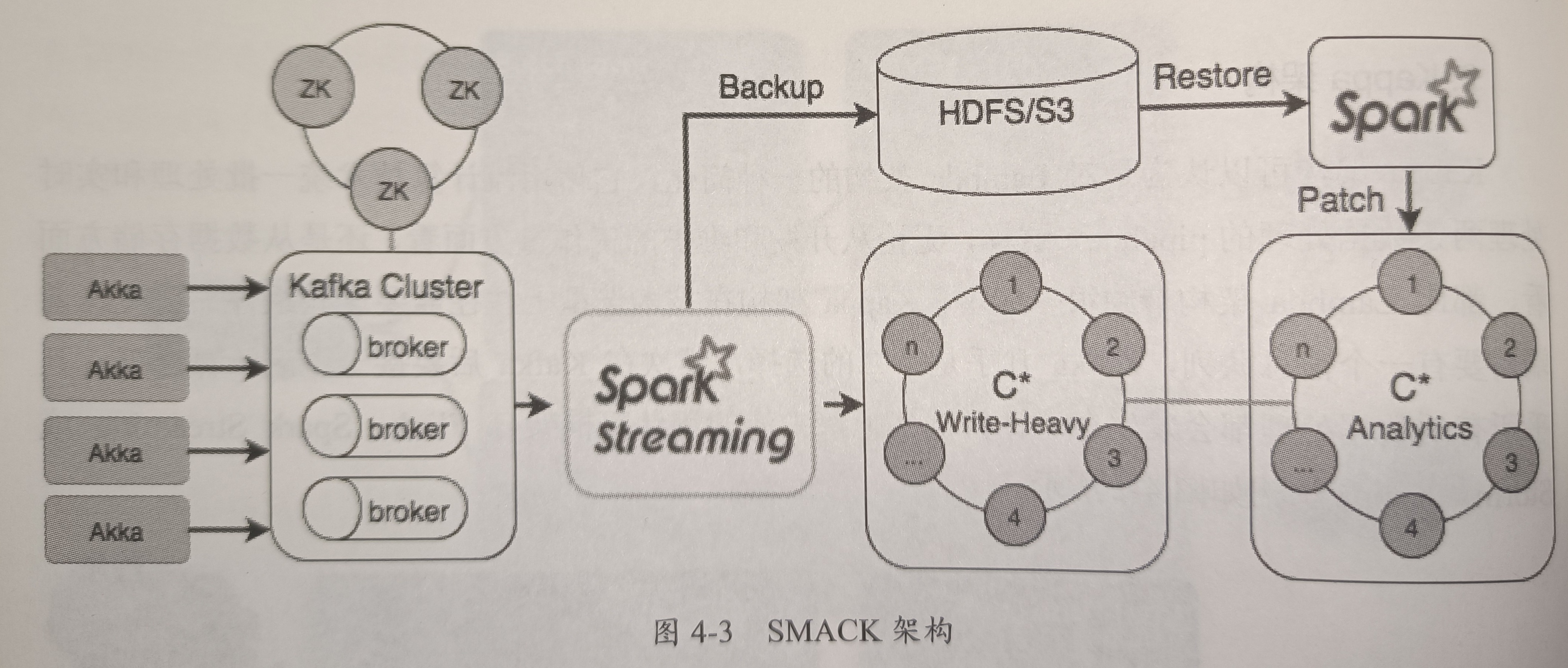
SAMCK架构使用Akka进行数据采集(Akka可以应对高并发和实时性要求很高的场景),然后将数据写入Kafka,接着使用Spark Streaming进行实时流处理,处理结果和原始数据都写入Cassandra,至此所有做法和Kappa架构是一样的。不同于Kappa,SMACK依然保有批处理能力,它巧妙地利用了Cassandra集群:一个集群专门用来接收流处理结果数据,另一个集群用于批处理分析,供Spark(Spark Core或 Spark SQL)读写
SMACK架构之既支持批处理又支持实时处理,在数据处理层面只依赖Spack,在数据存储层面只依赖Cassandra,统一了技术堆栈
原型项目架构方案
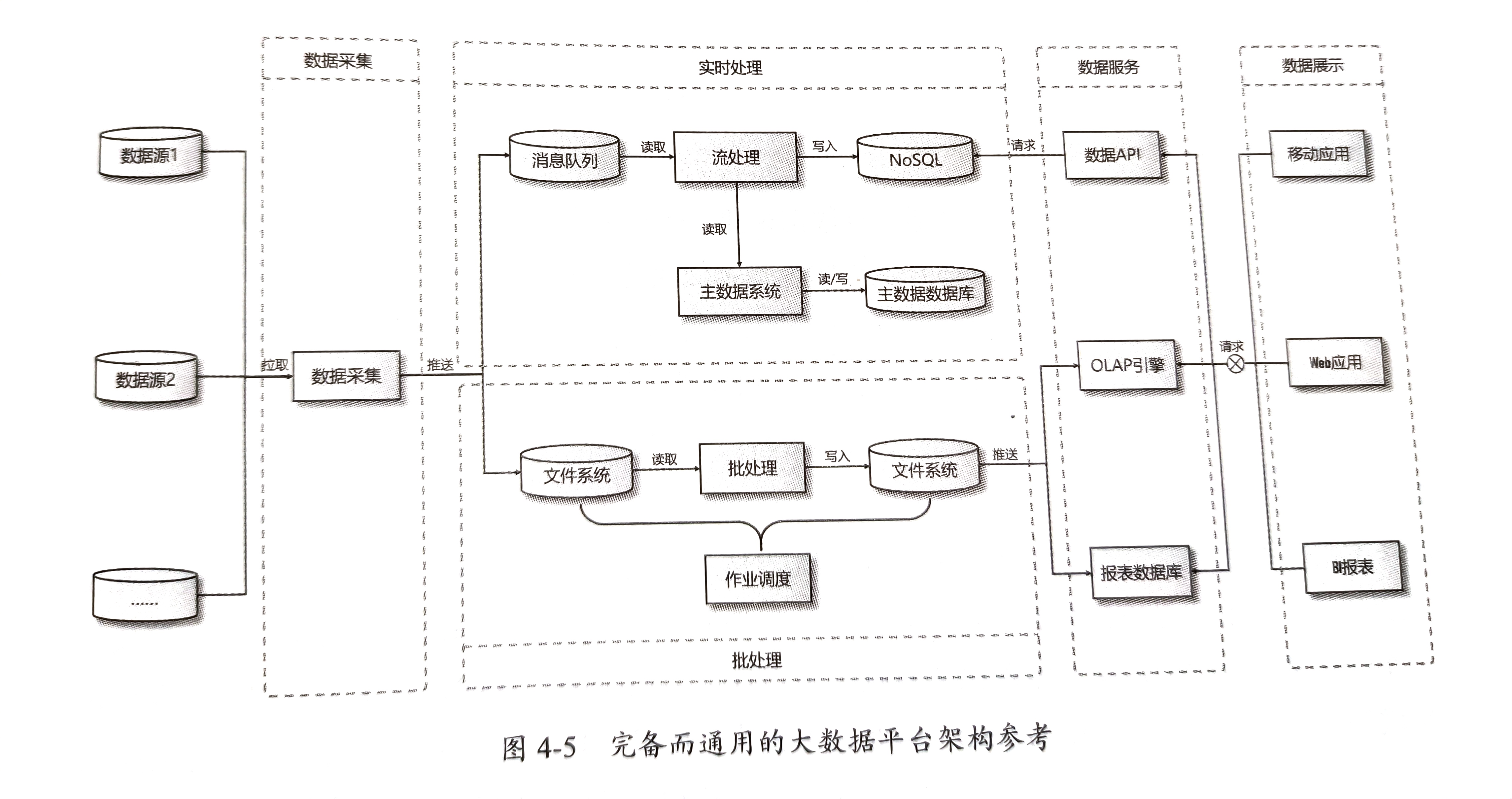
1.数据采集
主流工具:Flume、Logstash、Kafka Connect
数据采集组件:Apache Camel(技术选型)
2.消息队列
Kafka
3.流处理
Storm、 Spark Streaming(技术选型)
4.批处理
Hive、Spark SQL、Spark Core+Spark SQL(技术选型)
5.主数据管理
Springboot+Mysql+Redis(技术选型)
6.数据服务
HBase(技术选型)、Cassandra、MongoDB
7.数据展示
 wechat
wechat alipay
alipay
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)